
티스토리 뷰
역 인덱스 (Inverted index)
텍스트 분석 과정 (Text Analysis)
- Tokenizer
- Token Filter
- _analyze API 를 이용한 분석 테스트
사용자 정의 analyzer
텍스트 필드에 analyzer 적용
_termvectors API 를 이용한 term 확인
역 인덱스 (Inverted index)
EL은 역인덱스로 저장을 합니다.
데이터 시스템에 다음과 같은 문서들을 저장한다고 가정 해 보겠습니다.

일반적으로 오라클이나 MySQL 같은 관계형 DB에서는 위 내용을 보이는 대로 테이블 구조로 저장을 합니다. 만약에 위 테이블에서 Text 에 fox가 포함된 행들을 가져온다고 하면 다음과 같이 Text 열을 한 줄씩 찾아 내려가면서 fox가 있으면 가져오고 없으면 넘어가는 식으로 데이터를 가져 올 것입니다.

테이블 데이터에서 한 줄씩 like 검색
전통적인 RDBMS 에서는 위와 같이 like 검색을 사용하기 때문에 데이터가 늘어날수록 검색해야 할 대상이 늘어나 시간도 오래 걸리고, row 안의 내용을 모두 읽어야 하기 때문에 기본적으로 속도가 느립니다. Elasticsearch는 데이터를 저장할 때 다음과 같이 역 인덱스(inverted index)라는 구조를 만들어 저장합니다.
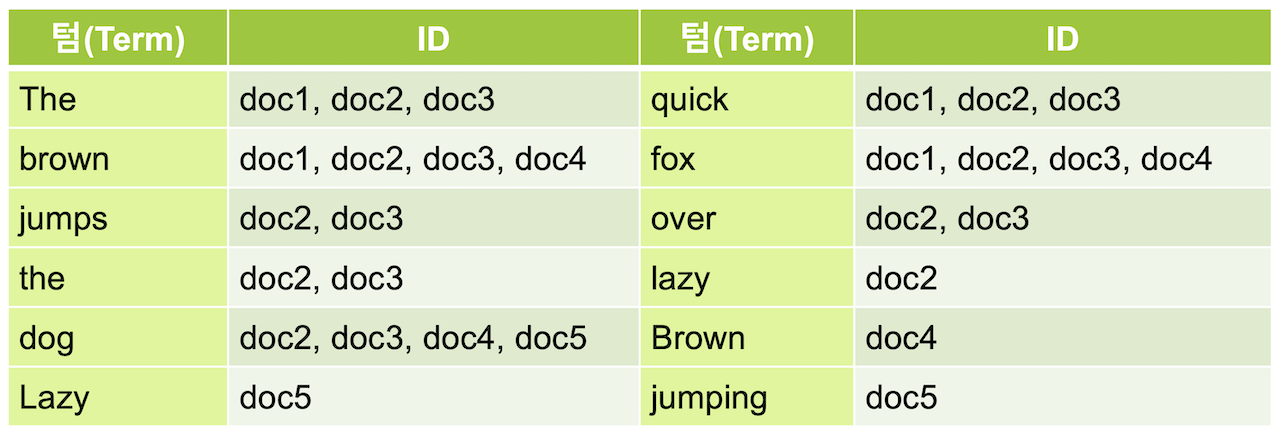
역 인덱스(Inverted Index) 구조
이 역 인덱스는 책의 맨 뒤에 있는 주요 키워드에 대한 내용이 몇 페이지에 있는지 볼 수 있는 찾아보기 페이지에 비유할 수 있습니다. Elasticsearch에서는 추출된 각 키워드를 텀(term) 이라고 부릅니다. 이렇게 역 인덱스가 있으면 fox를 포함하고 있는 도큐먼트들의 id를 바로 얻어올 수 있습니다.

Elasticsearch는 데이터가 늘어나도 찾아가야 할 행이 늘어나는 것이 아니라 역 인덱스가 가리키는 id의 배열값이 추가되는 것 뿐이기 때문에 큰 속도의 저하 없이 빠른 속도로 검색이 가능합니다. 이런 역 인덱스를 데이터가 저장되는 과정에서 만들기 때문에 Elasticsearch는 데이터를 입력할 때 저장이 아닌 색인을 한다고 표현합니다.
참고
'ELK 스택' 카테고리의 다른 글
| Elasticsearch - 인덱스 매핑과 데이터 타입 문자열, 숫자 (1) (0) | 2022.11.07 |
|---|---|
| Elasticsearch - 사용자 정의 애널라이저 (Custom Analyzer) (0) | 2022.11.07 |
| Elasticsearch - 애널라이저 (Analyzer) (0) | 2022.11.07 |
| Elasticsearch - 텍스트 분석 (Text Analysis) (0) | 2022.11.07 |
| ELK 설치(윈도우) (0) | 2022.11.03 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- logstash
- 키바나
- 문자
- Elasticsearch
- string
- Mappings
- NextJS 14
- 절대 경로 설정하기
- Query
- GIT
- Mapping
- bool
- index 처리를 잘하자
- React18
- Java
- config
- EL
- Linux
- 인덱스
- mysql은 nl이 기본 세팅
- react
- ElasticSearach 백업
- InteiilJ
- literal sql
- kibana
- list
- pm2-logrotate
- 재색인
- 명령어
- ArrayList
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
글 보관함